Batch Processing - Generate Cases#
This notebook demonstrates creating cases in batch and running them in parallel.
Create Cases in Batch#
The approach to create cases in batch following this procedure:
Load the base case from file
For each desired case output:
Alter parameters to the desired value
Save each system to a new case file
import andes
import numpy as np
from andes.utils.paths import get_case
andes.config_logger(stream_level=30) # brief logging
# create directory for output cases
!rm -rf batch_cases
!mkdir -p batch_cases
kundur = get_case('kundur/kundur_full.xlsx')
ss = andes.load(kundur)
We demonstrate running the Kundur's system under different loading conditions.
Cases are created by modifying the p0 of PQ with idx == PQ_0.
As always, input parameters can be inspected by accessing Model.as_df(vin=True).
p0_base = ss.PQ.get('p0', "PQ_0")
Create 3 cases so that the load increases from p0_base to 1.2 * p0_base.
N_CASES = 3 # Note: increase `N_CASES` as necessary
p0_values = np.linspace(p0_base, 1.2 * p0_base, N_CASES)
for value in p0_values:
ss.PQ.alter('p0', 'PQ_0', value)
file_name = f'batch_cases/kundur_p_{value:.2f}.xlsx'
andes.io.dump(ss, 'xlsx', file_name, overwrite=True)
Parallel Simulation#
Parallel simulation is easy with the command line tool.
Change directory to batch_cases:
import os
# change the Python working directory
os.chdir('batch_cases')
!ls -la
total 56
drwxr-xr-x 2 hacui hacui 4096 Apr 19 20:31 .
drwxr-xr-x 6 hacui hacui 4096 Apr 19 20:31 ..
-rw-r--r-- 1 hacui hacui 14841 Apr 19 20:31 kundur_p_11.59.xlsx
-rw-r--r-- 1 hacui hacui 14842 Apr 19 20:31 kundur_p_12.75.xlsx
-rw-r--r-- 1 hacui hacui 14840 Apr 19 20:31 kundur_p_13.91.xlsx
Running from Command line#
!andes run *.xlsx -r tds
_ _ | Version 1.6.4.post10.dev0+gd1a4589d
/_\ _ _ __| |___ ___ | Python 3.9.10 on Linux, 04/19/2022 08:31:06 PM
/ _ \| ' \/ _` / -_|_-< |
/_/ \_\_||_\__,_\___/__/ | This program comes with ABSOLUTELY NO WARRANTY.
Working directory: "/home/hacui/repos/andes/examples/batch_cases"
-> Processing 3 jobs on 12 CPUs.
Process 0 for "kundur_p_11.59.xlsx" started.
Process 1 for "kundur_p_12.75.xlsx" started.
Process 2 for "kundur_p_13.91.xlsx" started.
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
100%|########################################| 100.0/100 [00:01<00:00, 89.55%/s]
100%|########################################| 100.0/100 [00:01<00:00, 87.15%/s]
100%|########################################| 100.0/100 [00:01<00:00, 83.73%/s]
Log saved to "/tmp/andes-4fbaduja/andes.log".
-> Multiprocessing finished in 1.7566 seconds.
Number of CPUs#
In some cases, you don't want the simulatino to use up all resources.
ANDES allows to control the number of processes to run in parallel through --ncpu NCPU, where NCPU is the maximum number of processes (equivalent to the number of CPU cores) allowed.
!andes run *.xlsx -r tds --ncpu 4
_ _ | Version 1.6.4.post10.dev0+gd1a4589d
/_\ _ _ __| |___ ___ | Python 3.9.10 on Linux, 04/19/2022 08:31:09 PM
/ _ \| ' \/ _` / -_|_-< |
/_/ \_\_||_\__,_\___/__/ | This program comes with ABSOLUTELY NO WARRANTY.
Working directory: "/home/hacui/repos/andes/examples/batch_cases"
-> Processing 3 jobs on 4 CPUs.
Process 0 for "kundur_p_11.59.xlsx" started.
Process 1 for "kundur_p_12.75.xlsx" started.
Process 2 for "kundur_p_13.91.xlsx" started.
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
100%|########################################| 100.0/100 [00:01<00:00, 88.46%/s]
100%|########################################| 100.0/100 [00:01<00:00, 86.36%/s]
100%|########################################| 100.0/100 [00:01<00:00, 83.39%/s]
Log saved to "/tmp/andes-rlpeyxo9/andes.log".
-> Multiprocessing finished in 1.7693 seconds.
Running with APIs#
Setting pool = True allows returning all system instances in a list.
This comes with a penalty in computation time but can be helpful if you want to extract data directly.
systems = andes.run('*.xlsx', routine='tds', pool=True, verbose=10)
Working directory: "/home/hacui/repos/andes/examples/batch_cases"
Found files: ['kundur_p_11.59.xlsx', 'kundur_p_12.75.xlsx', 'kundur_p_13.91.xlsx']
-> Processing 3 jobs on 12 CPUs.
Cases are processed in the following order:
"kundur_p_11.59.xlsx"
"kundur_p_12.75.xlsx"
"kundur_p_13.91.xlsx"
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
<Toggle 1>: Line.Line_8 status changed to 0 at t=2.0 sec.
Log saved to "/tmp/andes-lmohp4sw/andes.log".
-> Multiprocessing finished in 3.2217 seconds.
systems[0]
<andes.system.System at 0x7fbaa050a070>
systems
[<andes.system.System at 0x7fbaa050a070>,
<andes.system.System at 0x7fba7bca2c70>,
<andes.system.System at 0x7fba7bc9db80>]
Example plots#
Plotting or data analyses can be carried out as usual.
ss = systems[0]
systems[0].TDS.plotter.plot(ss.GENROU.omega, latex=False)
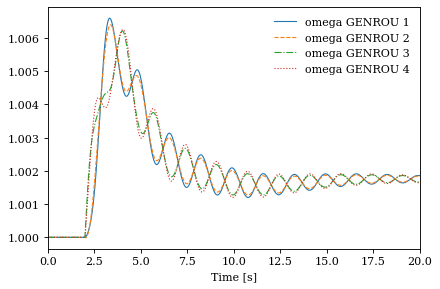
(<Figure size 480x320 with 1 Axes>, <AxesSubplot:xlabel='Time [s]'>)
systems[2].TDS.plotter.plot(ss.GENROU.omega, latex=False)
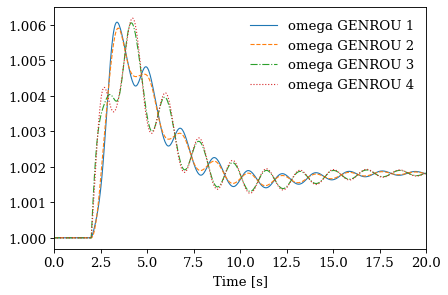
(<Figure size 480x320 with 1 Axes>, <AxesSubplot:xlabel='Time [s]'>)
!andes misc -C
!rm -rf batch_cases
No output file found in the working directory.